産業/信頼性
10.抜き取り試験
大きな母集団から少数の試料を採ってその寿命を測定し、そのデータから母集団の平均寿命を推定するという統計学的方法を前項まで説明してきました。寿命試験はどうしても長い試験時間を必要とします。この間、デバイスを動作させ続けることになりますから、試験に要するコストも考えると少数の試料について試験し、母集団については合理的に推定する方法がとられます。
このように多数のなかから少数のサンプルを抜き取って試験する試験方法を抜き取り試験と言います。前項までの方法も抜き取り試験の一種と言えますが、その目的は検査対象の寿命の値を知ることにありました。一方、抜き取り試験(または抜き取り検査)というとむしろ品質管理のために行われる検査を言う場合が一般的かもしれません。これは大量に製造された製品を顧客に販売するに際して、不良品が流出するのを防ぐため、製品の一部を試料として採り、それを定められた方法で測定して製品として出荷してよいかどうかを判定します。
寿命を合否判定に使う場合、試験は破壊試験ですから製品について全数検査をするわけにはいきません。一方、検査がサンプルを破壊や劣化させるなどの影響がない場合には、全数を検査する方が品質管理のためにはもっとも確実です。しかし検査に要する時間とコストを削減するために、このような場合にも抜き取り検査が多く行われます。
抜き取り検査の問題点は全体の一部を検査するだけなので、検査結果が全体の状態を正確に示すものではないことです。このため一部の検査結果から全体の状態を合理的に推定することが必要です。
もちろん信頼性はどの製品にも共通する重要な品質ですが、寿命試験と一般の品質管理のための検査では使われる用語がいくらか異なっていたりするため、ここでは寿命の評価のための抜き取り試験に絞って説明します。
具体的な試験の方法はつぎのようになります。まずあるひとまとまりの製品を母集団(個数を \(N\) 個とします)と決めます。これを品質管理ではロット(lot)と言います。ロット内の製品は均一とみなせる必要があり、はじめから同一ロット内に性質が異なるものが含まれないようにします。このため、試験するロットに含まれる製品は同じ条件で作られたものであることが望ましいと言えます。例えば、同じ日に同じ工程で同じ作業者によって製造された一群の製品などをロットとします。
この母数 \(N\) 個のロットから \(n\) 個の標本(サンプル)を抜き取って試験にかけます。\(n\) をどれくらいの数とするかについては後で触れますが、\(N/10\) 以下ぐらい、母集団より十分少ない数にするのが普通です。\(n\) を大きくするほど検査結果はロットの真の状態を反映するようになりますが、これでは抜き取りによって試験の数を減らすという意味がなくなります。
またサンプルの抜き取り方は無作為(ランダム)に偏りをもたないようにする必要があります。母集団の真の状態をできるだけ正しく反映するようにするためです。最初に製造した順に \(n\) 個とか最後の \(n\) 個とかいった偏った抜き取り方はしないようにします。厳密にするなら乱数表を利用するなどしてランダムにサンプルを抜き取ります。
この \(n\) 個のサンプルを所定の条件のもとで試験にかけ、故障の発生を調べます。ここで2種類の考え方があります。一つはある基準となる時間を定め、この時間より短い時間で故障が発生したサンプルの個数を数える方法です。その結果、故障した個数がある定められた数(\(c\)個)以下であれば、そのロットを合格と判定し、\(c+1\) 個以上なら不合格とします。この方法を計数抜き取り法と言います。
もう一つの方法は故障の発生時間をそれぞれのサンプルで測定し、その平均値を求め、これが所定の値より長ければそのロットは合格、短ければ不合格とする方法です。このような方法を計量抜き取り法と言います。すべてのサンプルが故障するまで行うには時間がかかりますから、試験は一定の時間まで行い、その時点で試験を打ち切っても構いません。
上記のように \(N\) 個の母集団(ロット)から抜き取ってきた \(n\) 個のサンプルのうち \(k\) 個が所定時間内に故障する確率 \(P \left(k \right )\) は、つぎのように計算できます。
まず母集団から \(n\) 個を無作為に取り出す組み合わせの数は \(_{N}\mathrm{C}_n\) です。このうち \(k\) 個が故障を起こし、かつ\(n-k\) 個が故障しない組み合わせの数は、\(_{K}\mathrm{C}_k\cdot _{N-K}\mathrm{C}_{n-k}\) です。ただし母集団全体で故障を起こす数は \(K\) 個とします。したがって、抜き取った \(n\) 個のサンプルのうち \(k\) 個が所定時間内で故障する確率 \(P \left(k \right )\) は、\[\begin{align}P \left ( k \right ) &= \frac{_{K} \mathrm{C}_{k}\cdot{ _{N-K}} \mathrm{C}_{n-k}}{_{N}\mathrm{C}_{n}} \\ &= \frac{ _{n} \mathrm{C}_{k} \cdot{_{N-n}} \mathrm{C}_{K-k}}{_{N} \mathrm{C}_{K}} \tag{1}\end{align}\] ここで \( _{x}\mathrm{C}_{y}\) は \(x\) 個の集団から 個々に区別のない \(y\) 個を抜き取る場合の数で、 \[_{x}\mathrm{C}_{y}=\frac{x!}{y!\left( x-y \right )!}\] を意味し、組合せ(combination)と呼ばれます。また(1)式は超幾何分布と呼ばれる確率分布関数です。
二項分布と呼ばれる確率分布関数もよく知られています。こちらは上記と同じ \(K\) 個の故障を含む \(N\) 個の母集団から1個を抜き出して故障するか否かを調べ、これを母集団に戻してから、再び1個を抜き取るというやり方で計 \(n\) 個を調べた結果、故障が計 \(k\) 回発生する確率で、つぎのように表されます。 \[P \left (k \right )= _n \mathrm{C}_{k} \cdot \lambda^k \left ( 1-\lambda \right )^{n-k}\tag{2}\] ここで \(\lambda=K/N\) であり、これは5項で定義した故障率に相当します。
故障の場合は起きてしまうと元には戻せないので、本来はこの分布関数は使えないのですが、\(N \gg n\) であれば超幾何分布は二項分布で近似されます。抜き取ったものを戻しても戻さなくても大差がないからです。計算は超幾何分布より二項分布の方が簡単なので、従来から計算には通常、二項分布が使われています。ただしこれも表計算ソフト(Excel)に両方の関数が用意されているので、もはや計算が簡単な方の式をあえて使う意味はあまりありませんが。
ここで故障したサンプルの数が \(k=c\) 個以下であれば合格とするとすると、その確率は \(k\) が 0 個から \(c\) 個までである累積の確率となります。この累積確率 \(P \left (k \le c\right )\) は \[\begin{align}P \left ( k \le c\right ) &= \sum_{k=0}^{c} P\left ( k\right ) \\ &= P \left ( 0\right )+P \left ( 1\right )+\cdots +P \left ( c\right )\end{align}\tag{3}\]と書けますから \(P \left (k \le c\right )\)は \(\lambda \) の関数であり、\(P \left ( \lambda \right )\) と置き換えることができます。これを合格確率と呼びます。
なお故障率 \(\lambda\) は5項で示した故障分布関数 \(F \left ( t\right )\) に相当しますから、 \[\lambda=F \left ( t_i \right ) =1-R \left ( t_i \right )\] と書けます。ただし \(R \left (t \right )\) は信頼度関数、\(t_i\) は試験時間です。 (2)、(3)式より試験時間 \(t_i \) 内に発生した故障数が \(c\) 以下である確率 \(P \left (\lambda \right)\) は \[P \left ( \lambda \right ) =\sum_{k=0}^{c} \left [_n\mathrm{C}_{k} \lbrace 1-R \left (t_i \right )\rbrace^k \lbrace R \left (t_i \right )\rbrace^{n-k}\right]\] と表されます。 ここで故障確率密度関数がワイブル分布に従っているとすれば、信頼度関数 \(R\left (t_i \right )\)は \[R \left ( t_i \right ) = \exp \left (-\frac{t_i}{\eta}\right )^m \] と表されます。ただし \(\gamma\) は省略しました。
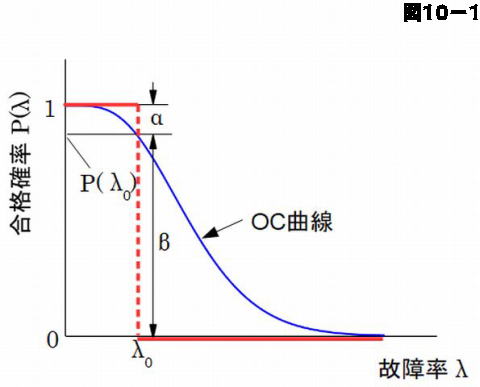
この故障率 \(\lambda \) の関数としての合格確率 \(P \left ( \lambda \right )\) も \(n\) と \(c\) を与えると、表計算ソフト(Excel)を用いて計算することができます。図10-1の青色で示す曲線がその一例で、この曲線をOC曲線と呼んでいます。OCは"Operating Characteristic"の頭文字であり、日本語では「検査特性曲線」と訳されています。この曲線は品質管理のためにむしろよく使われます。この場合、横軸は不良率となります。
図10-1を見るとOC曲線は故障率(品質管理では不良率) \(\lambda \) が 0 に近づくと合格確率 \(P \left ( \lambda \right )\) は 1 に近くなっています。これはロットの故障率が 0 に近いときは、抜き取り検査によって合格する確率が大きくなることを示しています。また曲線が右下がりの減少関数になっていることは、ロットの故障率が大きくなると合格する確率が小さくなり不合格になる確率が大きくなることを示しています。これは普通に予想される特性と言えます。
いま故障率が \(\lambda_0 \) より小さければ合格にするとします。ロットの全数を試験すれば、\(\lambda_0 =K_0 /N\) が決まりますから、図の赤線で示したように合格、不合格の境はきちんと定まります。しかし抜き取り試験の場合は、確率しかわからないので、図で \(\alpha \)と示した割合は本来合格なのに不合格と判定されてしまう恐れがあります。
品質管理の場合はとくに製品の売り手(販売者、生産者)と買い手(顧客、消費者)の関係で合格、不合格の基準が決まってきますが、寿命、故障も品質の一つですから、どちらも同じような取り扱いがなされます。このような観点に立てば、上記の \(\alpha \) は売り手にとってのリスクになりますから、これを生産者危険(生産者リスク)と呼びます。\(\alpha \)が大きいと売り手に不利になるので、売り手側の主張によってこれを小さくすると、今度は \(\beta \left ( =1-\alpha \right )\) が大きくなります。これは本来不良の(故障が起こる)ものが購入した製品に含まれる割合が増えることを意味し、\(\beta \) を消費者危険(消費者リスク)と呼んでいます。
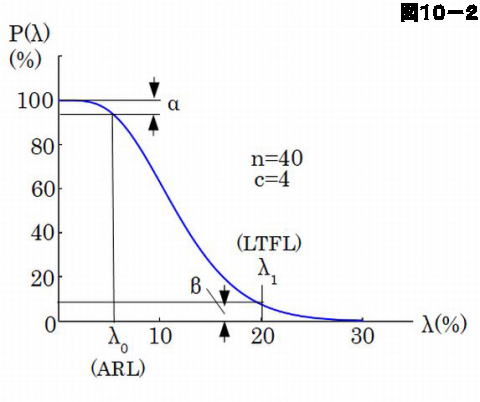
売り手と買い手の主張は相反するので、品質管理においては上記のようなOC曲線においてどのように両者の折り合いをつけるか、いろいろな手法が考えられています。その一つを図10-2により説明します。ここでは \(\lambda_0 \)と \(\lambda_1 \) という2つの基準を設けます。\(\lambda_0 \) の方は図10-1に示したものと同じで、生産者危険 \(\alpha \) を規定するものです。これを合格信頼度水準(ARL、Acceptable Reliability Limit)と呼びます。品質管理の場合の合格品質水準(AQL、Acceptable Quality Limit)の方が一般的によく知られていますが、これと区別した呼び方がされます。
これに対して独立にもう一つの基準 \(\lambda_1 \) を定めます。図示したようにこれは消費者危険 \(\beta \) の方を規定し、ロット許容故障率(LTFR、Lot Tolerance Failure Rate)と呼び、品質管理の場合の限界品質水準(LQL、Limiting Quality Level)に対応します。
これにより、売り手は \(\lambda \le \lambda_0 \) であれば販売でき、買い手は \(\lambda \gt \lambda_1 \) ならば受け入れない、ということになります。もし \(\lambda_0 \lt \lambda \le \lambda_1 \) になった場合は、この試験だけでは判断しないことにし、別の判断基準を講じることになりますが、売り手と買い手が独自に基準を定めることができる利点があります。
典型的には \(\alpha =0.05 \left ( 5 \% \right )\)、\(\beta =0.1 \left ( 10 \% \right )\) 程度の値が設定されます。\(\lambda_0 \)と\(\lambda_1 \) は製品の性質によって決めます。例えば、\(\lambda_0 = 0.05 \left ( 5 \% \right )\)、\(\lambda_1 = 0.2 \left ( 20\% \right )\) などとします。ある条件で抜き取り試験をするためにはこの2点がOC曲線上に乗っていなければなりません。すなわち、 \[\begin{align} P \left (\lambda_0 \right ) &= 1-\alpha \\ P \left (\lambda_1 \right ) &= \beta \end{align}\tag{4}\] が成り立つように、(3)式を用いて \(n\)、\(c\) を求めることができ、上記2点を通るOC曲線が定まるので、それに従って抜き取り試験が行えます。
(4)式の連立方程式を正面から数値計算して解を求めてもよいですが、\(n\) は自然数、\(c\) は 0 を含む正の整数ですから、この2つの数を変えて複数のOC曲線を計算し、2点が曲線上に乗るようなものを得るのは表計算ソフトを使えば、手動でもそれほど困難ではありません。
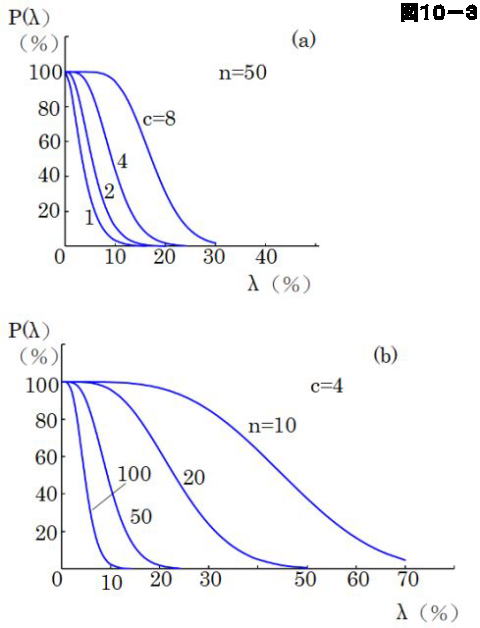
図10-3は \(n\) 固定で \(c\) を変えた場合(a)と \(c\) を固定し、\(n\) を変えた場合(b)のOC曲線の変化を示した例を示したものですが、\(c\) を変えると、曲線はほぼ平行移動しするのに対し、\(n\)を変えた場合は、\(n\) が大きくなると曲線の傾斜が大きくなる傾向があります。この変化を考慮して2点を1つの曲線上に乗るように近づけることが可能です。
図10-2はこのようにして得た \(\lambda_0 = 5 \% \)、\(\alpha = 5 \% \) と \(\lambda_1 = 20\% \)、\(\beta =10 \% \) の2点を(おおよそですが)通るOC曲線です。
品質管理においては製品の売り手と買い手がどこで折り合うかの問題、すなわち \(\alpha\) と \(\beta\) をどのように決めるかの問題です。これは不良品の混入が与える影響の大きさ、あるいは製造の困難さや製造方法の成熟度等々に依存する問題で一概に決定することは困難です。このため方法を標準化するため、抜き取り試験方法には種々の国内規格、国際規格が設けられています。これらは信頼性の問題からはかなり離れるので、ここでは立ち入りません。
<Excel関数>
超幾何分布
関数形=HYPGEOM.DIST(x,n,X,N,FUNC)
引数: x: 事象が起こる回数、n: 標本数、X: 母集団で事象が起こる回数、N: 母集団の数 、FUNC: 出力の種類:TRUE:累積密度関数、FAULSE:確率密度関数
.
二項分布
関数形=BINOM.DIST(x,N,,r,FUNC)
引数: x: 成功数、N: 試行数、r: 成功率、FUNC: 出力の種類、同上