産業/信頼性
8.平均寿命の区間推定(その1)
前項で平均寿命の推定値を求めました。この方法を点推定と言いますが、これは少数(例は20個)の試料(統計学的には標本とかサンプルと言います)について実験により求めた寿命の値の平均値を計算したもので、同じ製品でも別の試料を採用すれば、当然ながら異なる平均寿命の値が得られるはずです。このため得られた平均寿命は必ずしも母集団の平均寿命とは一致しませんし、どの程度正しいかもはっきりしません。
そこでもう少し推定値を確からしく示す方法として区間推定という方法が用いられます。区間推定では推定値の下限と上限を定め、推定値がこの下限から上限の間に入る確率を指定します。寿命でいえば、推定される平均寿命は指定した時間の範囲(区間)に例えば 95%の確率で入る、という言い方をします。95%の確率、つまり大方はその範囲内に入るけれども希に、つまり 5%の確率では範囲外になることもあります、という意味です。この範囲は狭くしたいところですが、狭くすると、その範囲内に入る確率も小さくなってしまいます。そこで範囲の広さと確率の関係を適度に定める必要があります。
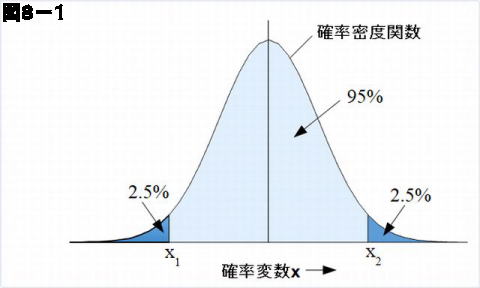
この範囲(区間)と確率の関係を決めるのが母集団での寿命がどのようなバラツキになっているかを表す確率分布関数です。これについては5~7項に渡って説明しました。例えば注目している母集団のなかの多数の要素(例えば製品)の寿命の値が図8-1のような分布にしたがっているとします。図は正規分布のように描かれていますが、前項まで説明してきたように必ずしも正規分布に限らず他の関数である場合もあります。
しかしどんな分布関数であっても全区間のなかに母集団に含まれるすべての製品の寿命の値が含まれるので、関数は全区間(\(x=-\infty \) から \(\infty \) まで)を積分すると1(面積=1)になります。ここで図のように関数の端(両端または片端)の一部を、面積が例えば 0.025(2.5%) ずつになるように \(x_1\) と \(x_2\) で切り取ると、残った中央部分の面積は 0.95(95%) になりますから、全体の内、\(x_1\) から \(x_2\) の間に推定しようとする値が入る確率は 95%になります。以下、具体例によって説明します。
まず母集団に含まれる寿命の値が正規分布である場合を考えます。3項で示した模擬データではデータ3がこれに近いので、これをモデルとして利用します。正規分布は5項で示したように \[f\left ( x\right )=\frac{1}{\sqrt{2\pi }\sigma }\exp \left [ -\frac{1}{2}\left ( \frac{x-\mu }{\sigma } \right)^{2} \right ]\tag{1}\] のように表されます。5項では確率変数が寿命時間であることから \(t\) で表していますが、後の都合があってここでは \(x\) を使います。(1)式の分布関数は母集団における寿命の平均値 \(\mu\) と分散 \(\sigma^2\) の2つのパラメータによって決まります。これは異なる平均値や分散に対して分布関数が変化することを意味し、取り扱いが不便です。そこで \[z=\frac{x-\mu}{\sigma}\tag{2}\] と変数を変換すると、分布関数は \[f\left (z\right )=\frac{1}{\sqrt{2\pi}}\exp \left (-\frac{z^2}{2} \right )\tag{3}\] となり、平均値、分散に依存しなくなります。これは平均値=0、分散=1の正規分布に相当し、これを標準正規分布と言います。(1)式の正規分布を \(N\left (\mu,\sigma \right )\) で示し、(3)式の標準正規分布を \(N\left (0,1 \right )\) と表すことがあります。ここで"N"は正規分布(Normal distribution)の頭文字です。正規分布の数値表はこの標準正規分布に対応した数値を示しています。実際の分布関数が必要な場合は、(2)式を使って \(z\rightarrow x\) の変換を行えばよいわけです。
さて、母集団が正規分布に従っている場合に、そこから \(n\) 個の標本を採り、その寿命の測定値を用いて母集団の平均値 \(\mu\) を推定します。一方の分散の値ですが、これもわからないのが普通です。平均値も分散もわからないとなると議論が進みませんから、分散の値にはサンプルのデータから計算できる値を使います。\(n\) 個のサンプルのデータを \(X_1,X_2,\cdots ,X_n\) とすると、このデータの分散(標本分散と言います)の値は \[S^2=\frac{1}{n}\sum\limits_{i=1}^n\left ( X_{i}-\overline{\mu}\right )^2 \] です。ここで \(\overline{\mu}\) は上記のデータから計算される平均値で \[\overline{\mu}=\frac{X_1+X_2+\cdots +X_n}{n}\] から計算されます。ところがこの標本分散と呼ばれる \(S^2\) はあまり使われず、次に示す不偏分散 \(s^2\) の値を使うのが普通です。 \[s^2=\frac{1}{n-1}\sum\limits_{i=1}^n\left ( t_{i}-\overline{\mu}\right )^2 \] 標本分散との違いは \(n\) で割っているか、\(n-1\) で割っているかだけで、不偏分散の方が少し大きい値となりますが、\(n\) が大きくなるとその差は小さくなります。この不偏分散を使う理由は一言で言うと、不偏分散の期待値が母分散の期待値に等しいからなのですが、これを証明していると脇道が長くなるのでここでは省略します。
平均値 \(\mu \)、分散 \(\sigma^2\) をもつ正規分布にしたがう母集団から n 個のサンプルを採り、そのデータ \(X_1,X_2,\cdots,X_n \) から母集団の平均値 \(\mu\) を推定します。
\(X_1+X_2+\cdots +X_n \) は、確率変数 \(t\) を \[t=\frac{\overline{\mu} - \mu}{\sqrt{\frac{s^2}{n}}}\] としたとき、自由度 \(\left (n-1 \right )\) の t 分布に従うことがわかっています。
t 分布は対称な分布ですが正規分布とは異なり、自由度というパラメータをもっています。この t 分布については確率密度関数 \(f\left (t\right )\) のみ掲げ、なぜこのような関数になるかの証明は省略します。なお、\(\Gamma \left (a\right )\) はガンマ関数です。
\[f\left (t\right )=\frac{\Gamma \left ( \left (n+1 \right )/2\right )}{\sqrt{n\pi}\Gamma \left (n/2 \right )}\left (\frac{t^2}{n}+1 \right )^{-\left (n+1 \right )/2}\]
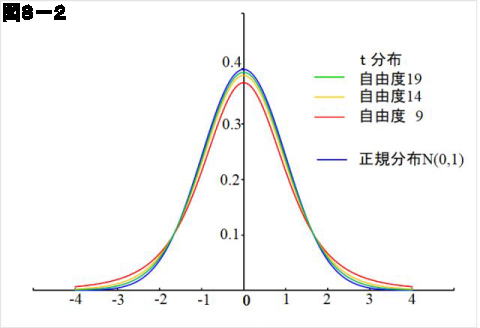
t 分布もExcelに関数が用意されています。自由度 9,14,19 として確率密度関数を計算し、標準正規分布と比較して示すと図8-2のようになります。t 分布は正規分布を押しつぶしたように広がった形をしていていますが、自由度が大きくなると正規分布に近づくのがわかります。
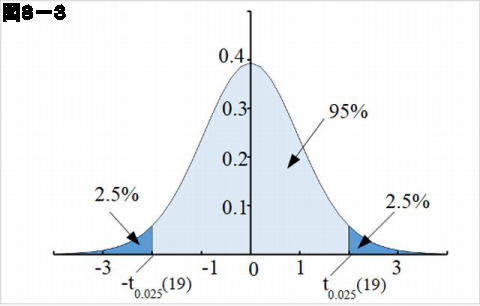
データ3を例に少し計算をしてみます。データ3では \(\overline{\mu}=474\) でしたから、これを使うと \[s^2 \simeq 40600\] となります。この値を用い、積分値が 0.025 になる値、これを \(t_{0.025} \left ( 19\right )\)と書くと、\(t_{0.025}\left ( 19\right )=2.093\) が得られます(図8-3参照)。
したがって平均寿命 \(\overline{\mu}\) の信頼度95%の信頼区間は \[\overline{\mu}-2.093\times \sqrt{\frac{s^2}{n}}\le \mu \le \overline{\mu}+2.093\times \sqrt{\frac{s^2}{n}} \]であることがわかります。\(n=20\)、\(\overline{\mu}=474\)、\(s^2=40600\) を代入すると、平均寿命 \(\mu\) の信頼度 95%の信頼区間は \[380\le \mu \le 568\]
であるということになります。
<Excel関数>
t 分布
関数形=T.DIST(t,n,FUNC)、この他にt分布に関連した関数が複数あります。
引数: t: 変数、n: 自由度、FUNC: 出力の種類 TRUE:累積密度関数、FAULSE:確率密度関数